 les derniers articles |
 Index & Sommaire |
 DÉCOLLAGE ! |
 Présentation du site WEB AILES |
Développement objet sous AGL : |
Les "Ateliers de Génie Logiciel" (dont le principe est présenté ici), sont devenus suffisamment efficaces pour être utilisés couramment par les ingénieurs d'études que vous êtes (c'est-à-dire par les développeurs dont le travail est présenté dans ce dossier). Cet article vise à présenter les "grands écarts intellectuels" que vous devez faire en manipulant cet outils. Il présuppose une connaissance de base d'UML 1.3. Les grands écarts sont mis en évidence en gras italique bleu, et ils sont au nombre de 4. |
Lisez-moi et réagissez ! |
Écrivez à AILES ! |
Article suivant : Dépendance entre Pckg. |
| Process vs Notation, ou
«j'veux un exe!» D'un côté, vous devez suivre un certain raisonnement intellectuel pour, à partir d'un problème donné, l'analyser, en faire une conception potable, le coder et le tester au moins une fois avant livraison. De l'autre, vous avez un AGL... basé sur UML. Et UML, c'est une no-ta-tion. C'est-à-dire quelque chose perçu comme fondamentalement statique, même si cette notation permet de décrire certains aspects dynamiques. Résultat ? Vous vous jetez sur le seul diagramme -statique- qui vous intéresse : le diagramme de classe. Vous posez vos classes et vos relations (héritage ou associations). Vous générez le code, compilez et priez pour obtenir l'exe voulu. Car le client, ce qu'il veut d'abord voir, c'est un exe. Pourquoi le diagramme de classe ? Parce que c'est le seul qui bénéficie d'une traduction automatique vers un code que vous pouvez ensuite compiler. (certes, le diagramme d'état est aussi traduit en code par certains AGL, mais il est -trop?- peu usité) Donc, voici le premier grand écart : l'utilisation d'un outils de notation statique dans le cadre d'un process de développement "hautement" dynamique (surtout lorsque le client change son cahier des charges en cours de route). Analyse vs Conception, ou «ça s'dégrade...» Nuançons de suite le premier grand écart mis en évidence : s'il est une partie du process dynamique pour laquelle les AGL actuels ont pour ambition de vous assister, c'est celle du passage de l'analyse à la conception. Enfin... de l'analyse détaillée à la conception. C'est à dire de la phase où vous avez identifié les grands packages et les grandes classes d'analyses, et celles où vous obtenez vos classes prêtes à être implémentées. Avant d'aborder ce cas, attardons-nous sur la première phase d'analyse, celle de spécification fonctionnelle. Les AGL n'arrivent pas encore à l'intégrer complètement. Le seul diagramme UML qui lui est réellement dédié reste celui des "Use Cases" ou « cas d'utilisation ». Les autres spécifs fonctionnelles restent à part, sous forme le plus souvent d'un document électronique (traitement de texte). D'où un deuxième grand écart (le premier du cas "Analyse vs Conception") : les cas d'utilisations restent rarement en cohérence avec les spécifs, d'une part, et avec la conception-codage d'autre part. (et B. Meyer critique cela) Concernant la cohérence spécif & cas d'utilisation, la raison est simple : il s'agit de 2 documents issus de 2 outils différents (traitement de texte, et AGL). Dans la pratique, on a jamais le temps de maintenir les deux : le développeur prendra le document de spécif et le plus souvent n'aura pas le temps de remettre à jour les cas d'utilisations. Surtout que cela ne lui sert pas à grand chose. En effet, aucun AGL ne propose de moyen simple de relier une conception à un ou plusieurs cas d'utilisation, permettant au développeur de : 1/ voir à quel(s) cas d'utilisation il est en train de répondre en posant sa classe dans son diagramme de classes, 2/ vérifier si ce cas d'utilisation est toujours en cohérence avec la connaissance qu'il a des besoins fonctionnels de l'application. Analyse vs Conception, ou «ça s'dégrade...bis» Parlons maintenant de la deuxième phase d'analyse, celle où vous modélisez. Ainsi, par exemple, vous avez bien identifié un écran IHM qui implique la saisie de données et l'affichage d'un résultat calculé. Fièrement, en respectant le paradigme MVC (Modèle-Vue-Contrôleur), vous posez vos classes d'analyses :
Votre analyse montre un calculateur
auquel on fournit des données et un écran de saisie
(puisqu'il ne fait que les référencer, par une simple
association et non une composition ou une agrégation). |
Analyse vs Conception, ou
«ça s'dégrade... bis» (suite et fin) Il s'agit plutôt de mettre en oeuvre un "design pattern" ou « pattern de conception » qui permettra de compléter vos classes afin de les rendre "opérationnelles" (donc prête à être générées puis implémentées) sans remettre en cause le couplage initial issu de votre analyse. Et là, avec les AGL actuels, c'est que du bonheur. En un clic de souris, vous appliquez sur les deux classes concernées (Calculateur et EcranIHM) le pattern « Observeur - Observé », et hop : 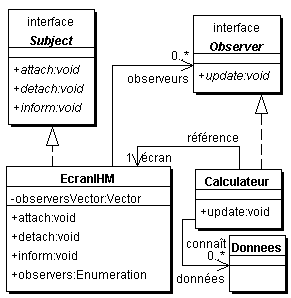 Mmmm... un poil touffu (si j'ose l'expression), non ? Si vous vous retrouvez encore dans ce fatras, vous constaterez que EcranIHM ne connaît pas Calculateur! Il connaît "Observer", classe qui appartient à un autre package que celui (Contrôleur) du Calculateur. Il n'y a pas de dépendance cyclique et l'Écran peut faire sa notification (à un "observer" dont il n'a que faire de l'identité réelle). Et où est le problème ? Aucun AGL ne propose de moyen simple de revoir le modèle d'analyse initial. Actuellement, il faut prendre ce modèle d'analyse et le dégrader en modèle de conception. Éventuellement, on aura pris soin d'en faire une copie avant de passer en conception... mais dans ce cas, rien ne garantit que ce modèle initial d'analyse reste cohérent bien longtemps avec la conception et le codage futur (à moins de générer plein de "refine"). Il s'agit donc d'un troisième grand écart : - non seulement l'analyse initiale se noie dans le brouhaha de conception, - mais en plus le développeur, pressé par le temps, va le plus souvent directement penser son Calculateur et son Ecran en tant qu'observeur-observé dans un cadre MVC. En posant ces classes (directement selon la deuxième figure), il combine ainsi à la fois une décision d'architecture technique (MVC) et un design de conception (observeur-observé). Bref, il fait tout en un, parce que seul la deuxième figure lui permet de générer quelque chose de compilable et d'avancer... Rq : en principe, UML propose une solution... qui n'est pas encore utilisée. Conception vs Codage, ou «planquez-moi ça! » Déjà évoqué dans les enjeux du développement objet sous AGL, il est important de toujours modéliser en planquant les choix d'implémentation. Ainsi, il ne faut pas voir cela :
Mais bien ceci : |



Décollage ! | Présentation du site web "AILES" |
Infos générales | articles "Informatique"